n8n 工作流自动化指南
n8n 工作流自动化指南
n8n 作为一个AI时代突然流行起来的工作流自动化工具,让我体验到了底代码的工作效率。现在测试了几个爬虫通过n8n来实现,再配合AI api来实现翻译和情感分析。记录一下n8n的安装过程和常用node
安装
n8n安装非常简单,docker和npm。两个都各有利弊吧。
docker:和本地环境隔离,如果需要额外的npm包,可能会有点麻烦。
npm:直接对接本地的node和npm环境,适合本地自己玩玩
我是用docker安装的,由于玩爬虫,我这里推荐n8n的第三方包 n8n-nodes-puppeteer 内置了 puppeteer
Docker
# 先根据 https://github.com/drudge/n8n-nodes-puppeteer 中自己做个images
# 在服务器上创建相关目录
mkdir -p ~/.n8n/custom
# 跑起来
docker run -d --name n8n \
-p 5678:5678 \
-v ~/.n8n:/home/node/.n8n \
-v ~/.n8n/custom:/home/node/custom \
-e N8N_CUSTOM_EXTENSIONS="/home/node/custom" \
n8n-puppeteer
# 如果想额外安装npm
cd ~/n8n/custom
npm init -y
npm install dayjs
# 重启一下
docker restart n8nnpm
emmmm... 没这么玩过,下面用的是chatgpt给的。看了下 官网 也差不多
# 安装
npm install -g n8n
# 跑起
n8n start
# 指定端口和主机跑起
N8N_PORT=5678 N8N_HOST=0.0.0.0 n8n start首次访问会让你注册,和激活(免费的)
然后,当当当当
核心概念
1. 工作流 (Workflow)
工作流是一系列连接的节点,定义了自动化任务的执行流程。
2. 节点 (Node)
节点是工作流的基本单元,每个节点执行特定功能。每个节点的数据会流转到下一个节点。
当然,你也可以在下一个节点获取前面所有节点的数据。
节点的逻辑有点像java的stream流,这一批数据处理完以后数据才会流转到下一个节点。
此网站可以看到所有的节点 节点大全
// 模拟 n8n 节点的数据流转
List<Map<String, Object>> data = Arrays.asList(
Map.of("id", 1, "name", "Alice", "status", "active"),
Map.of("id", 2, "name", "Bob", "status", "inactive")
);
// 节点1: 过滤数据(类似 n8n 的 IF 节点)
List<Map<String, Object>> filtered = data.stream()
.filter(item -> "active".equals(item.get("status")))
.collect(Collectors.toList());
// 这一批数据(2条)处理完后,才会流转到下一个节点
// 节点2: 转换数据(类似 n8n 的 Set 或 Code 节点)
List<Map<String, Object>> transformed = filtered.stream()
.map(item -> {
Map<String, Object> newItem = new HashMap<>(item);
newItem.put("name", ((String) item.get("name")).toUpperCase());
newItem.put("processed", true);
return newItem;
})
.collect(Collectors.toList());
// 上一节点的输出作为这一节点的输入
// 节点3: 聚合数据(类似 n8n 的 Code 节点进行聚合)
int totalCount = transformed.size();
// 可以访问前面所有节点的处理结果3. 执行 (Execution)
每次工作流运行都会创建一个执行记录,包含输入、输出和状态信息。
我的常用节点
先新建工作流
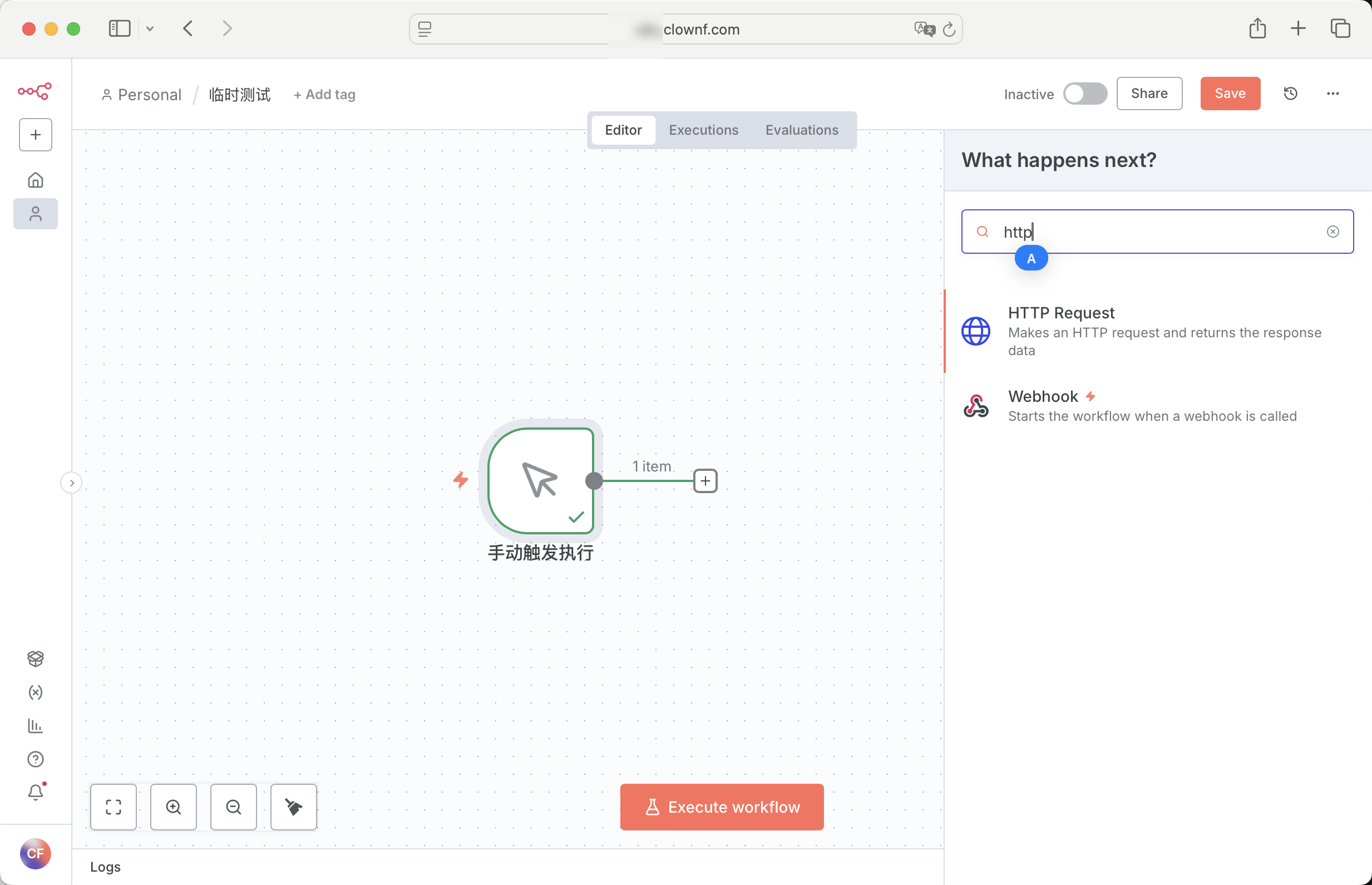
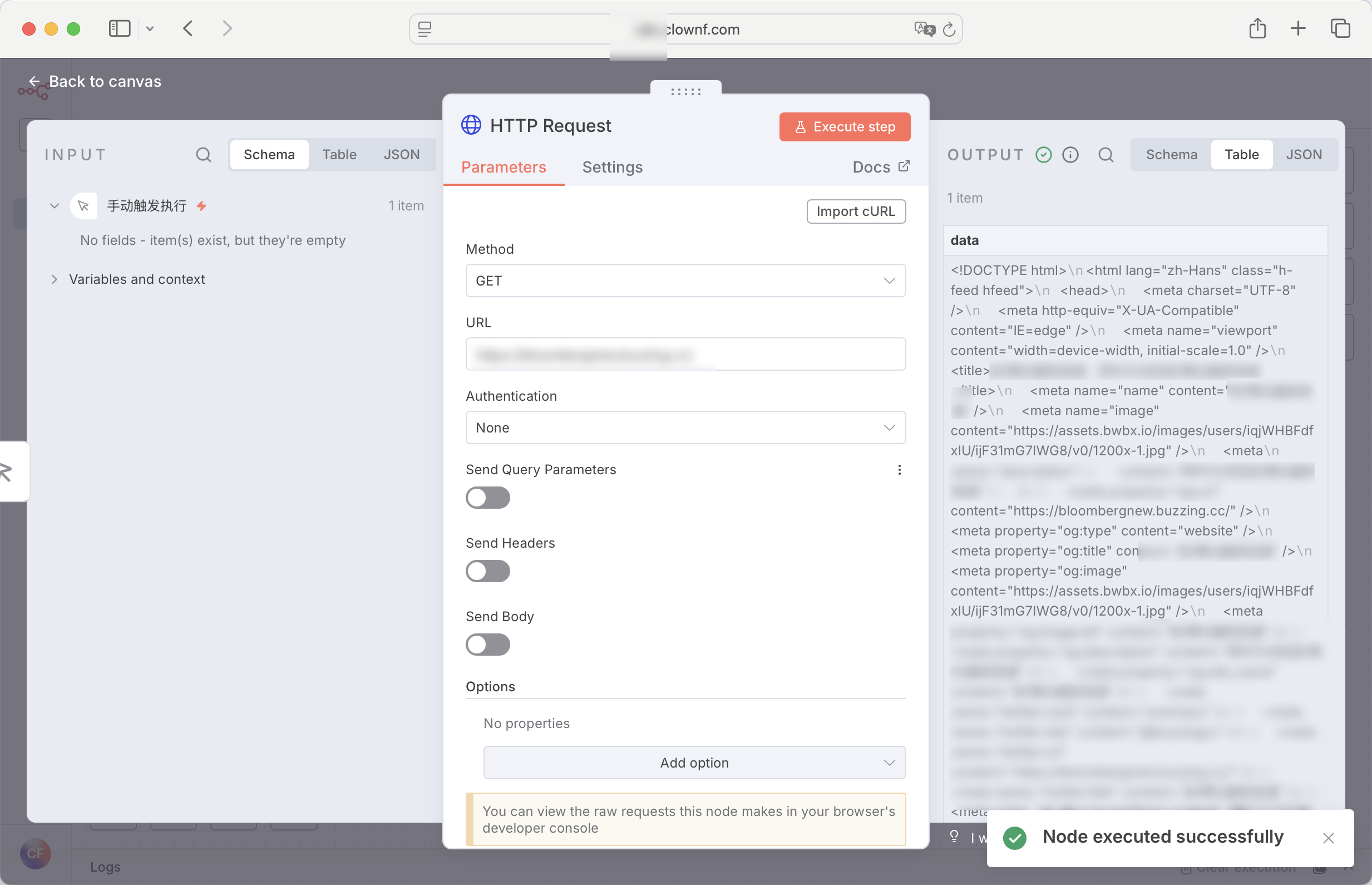
HTTP Request 节点
发送 HTTP 请求,支持 GET、POST、PUT、DELETE 等方法。
返回格式会根据请求的网址或api改变,我经常用来请求一些 免费的ai api和一些简单的爬虫
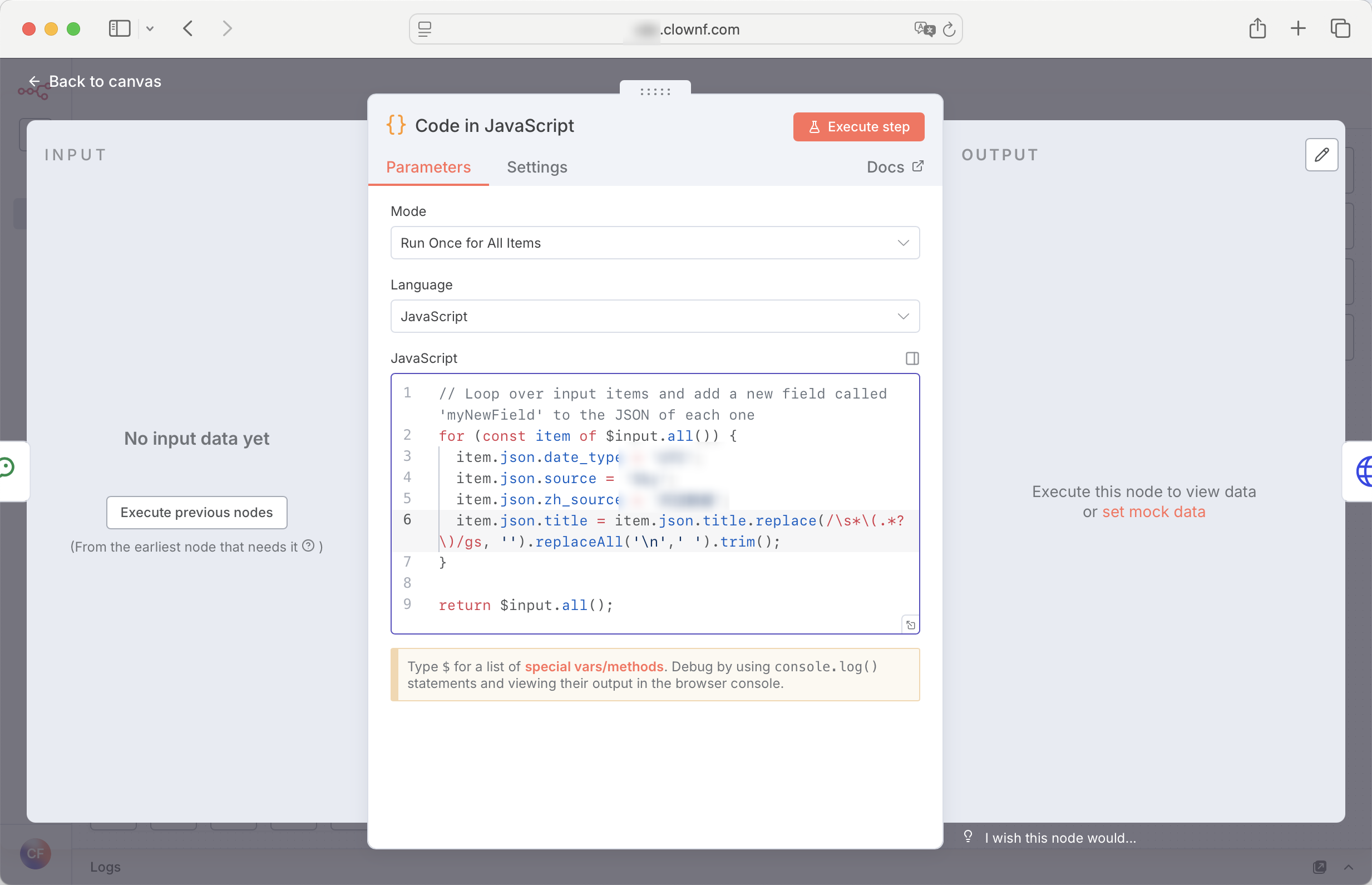
Code 节点
执行自定义 js 代码,或者py代码。自由度更高
IF 节点
条件判断,根据条件分支执行不同路径。
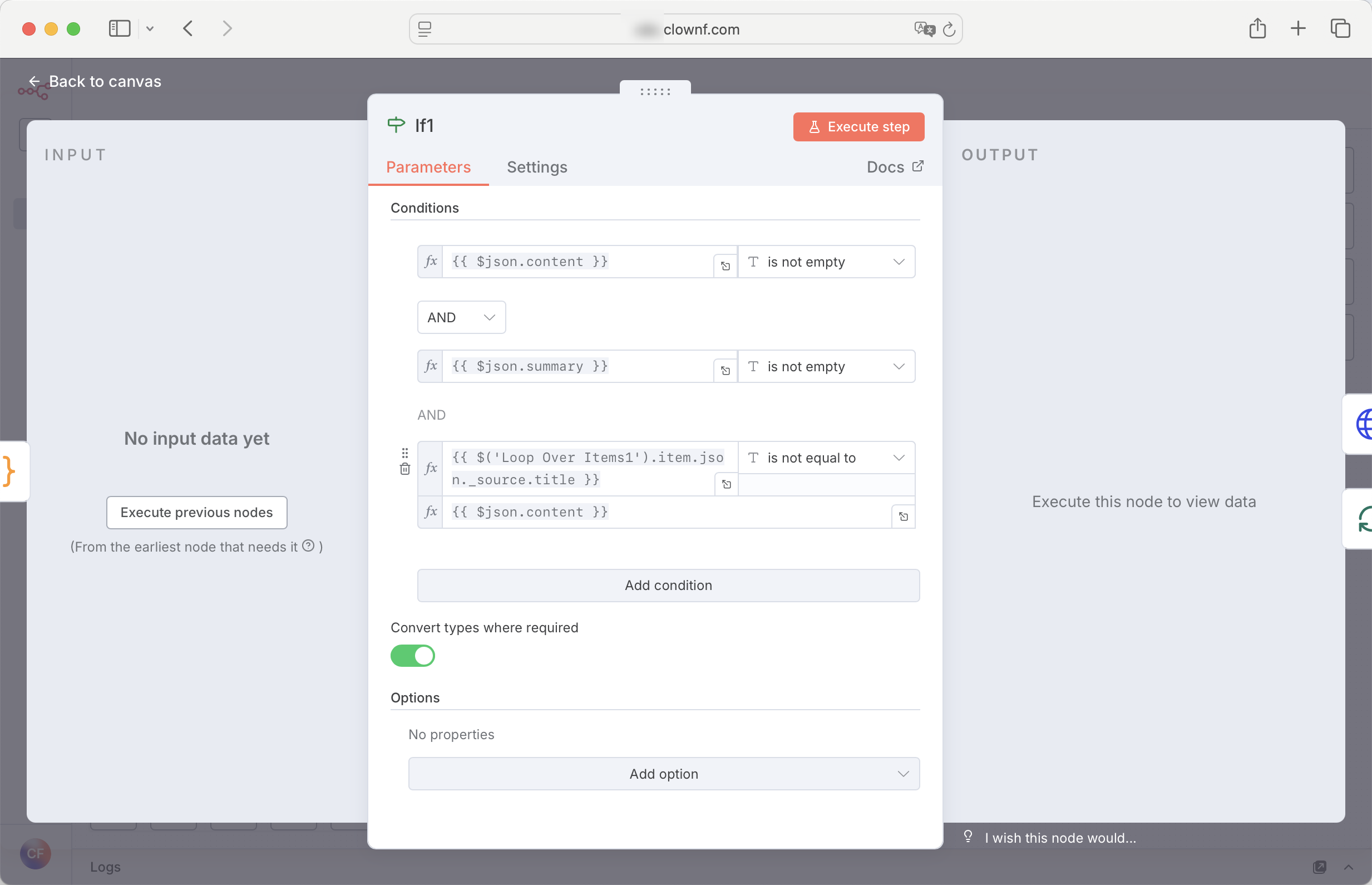
Set 节点
设置或修改数据字段。我用来组合以前所有节点的数据,组合成完整的数据,一般是入库节点的上一个节点
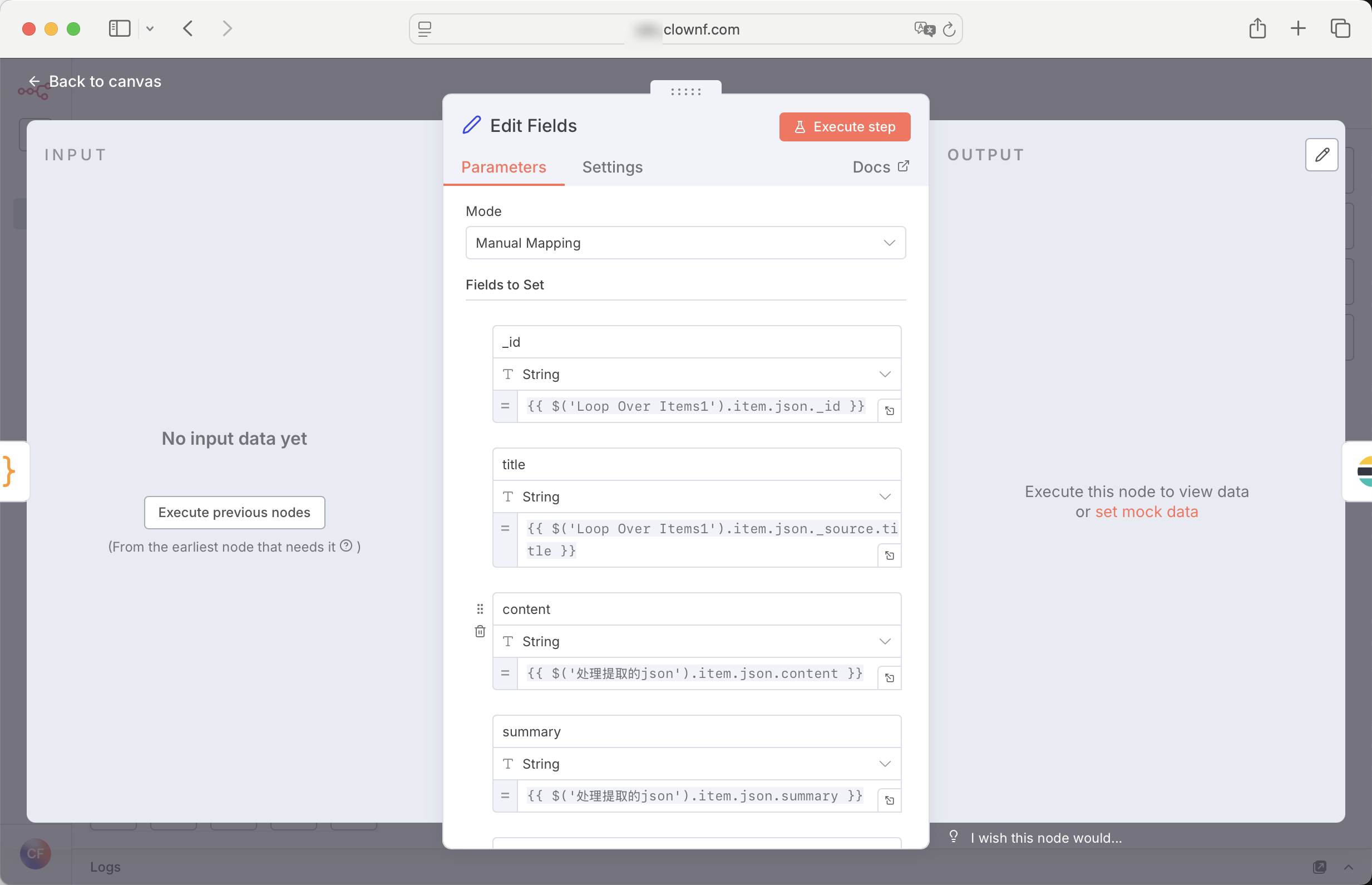
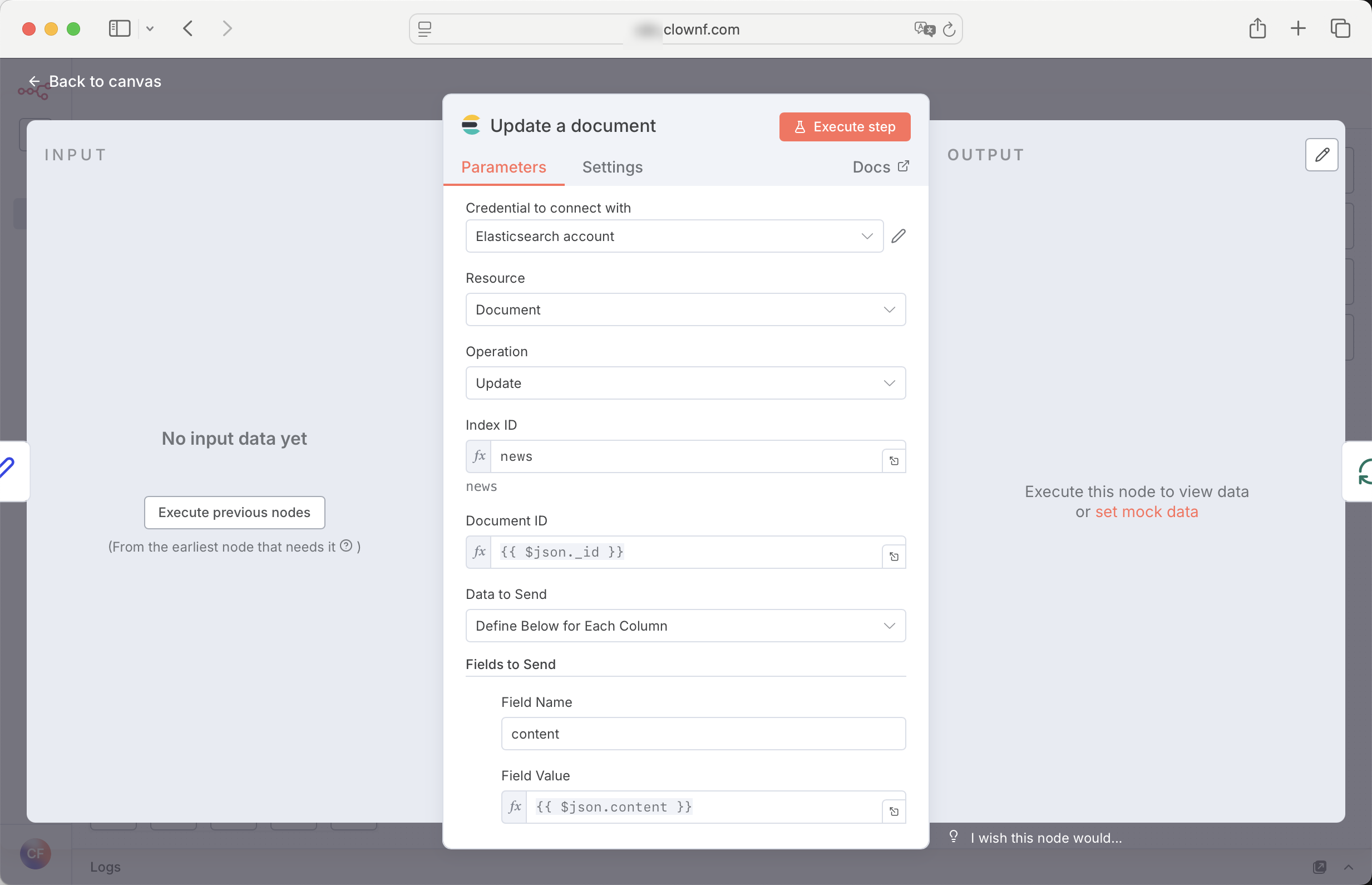
ES 节点
将数据存到es,完活儿!
当然,也有datebase节点存到数据库
⬇️还有一些很有意思的节点,对我来说帮助也很大。⬇️
JINA AI
这是一个 JINA AI AI搜索底座,可以帮助你去通过URL获取网站数据。我主要用来规避IP封锁的问题。爬虫网站不会知道你的IP。
但是,此节点必须要key,而key有额度限制。
所以我的建议是 使用 HTTP Request 节点 访问。 这样不需要key 20rpm,完全够用了~
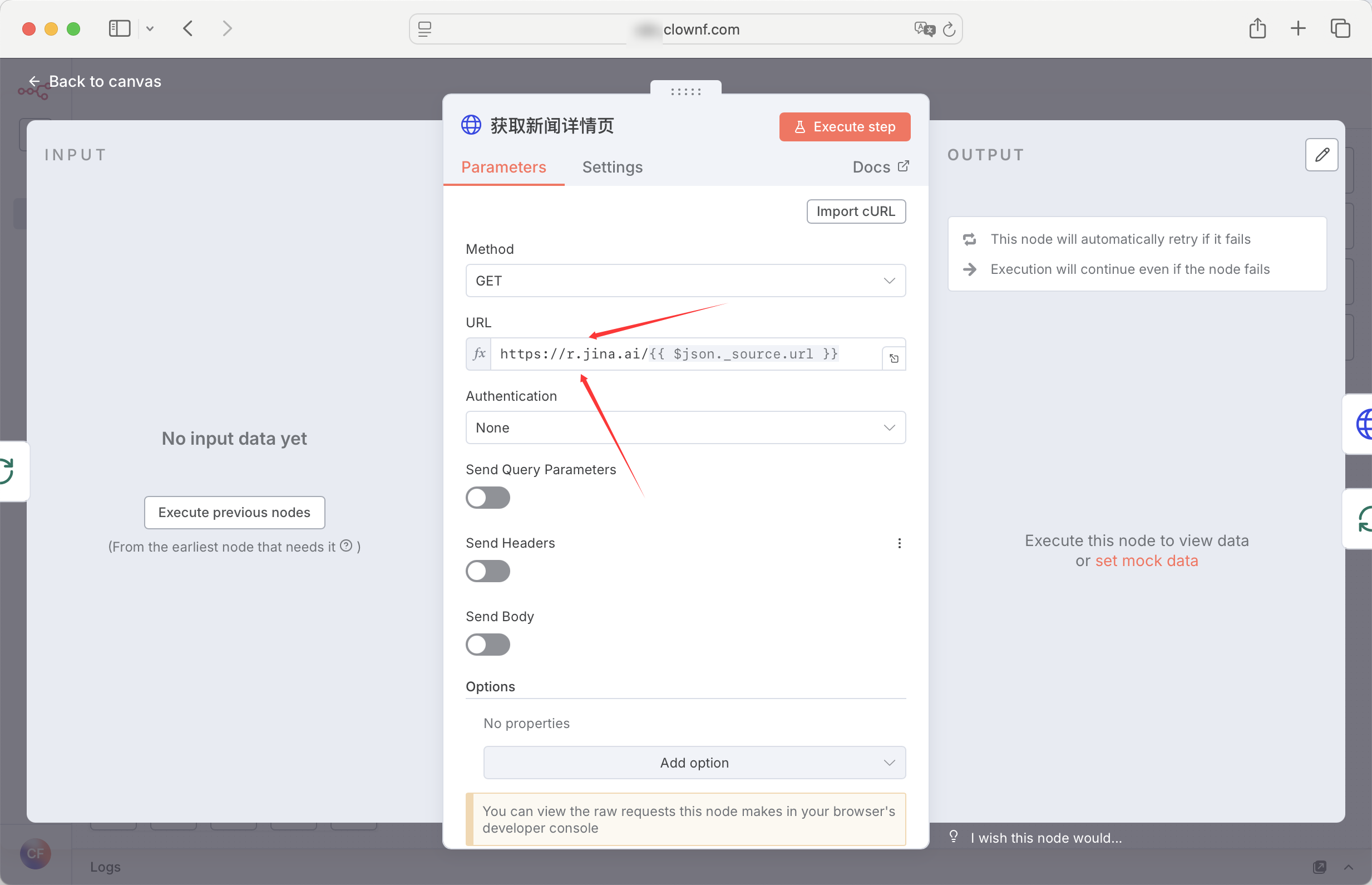
完整事例
一个超级简单的爬虫,只抓取列表的那种
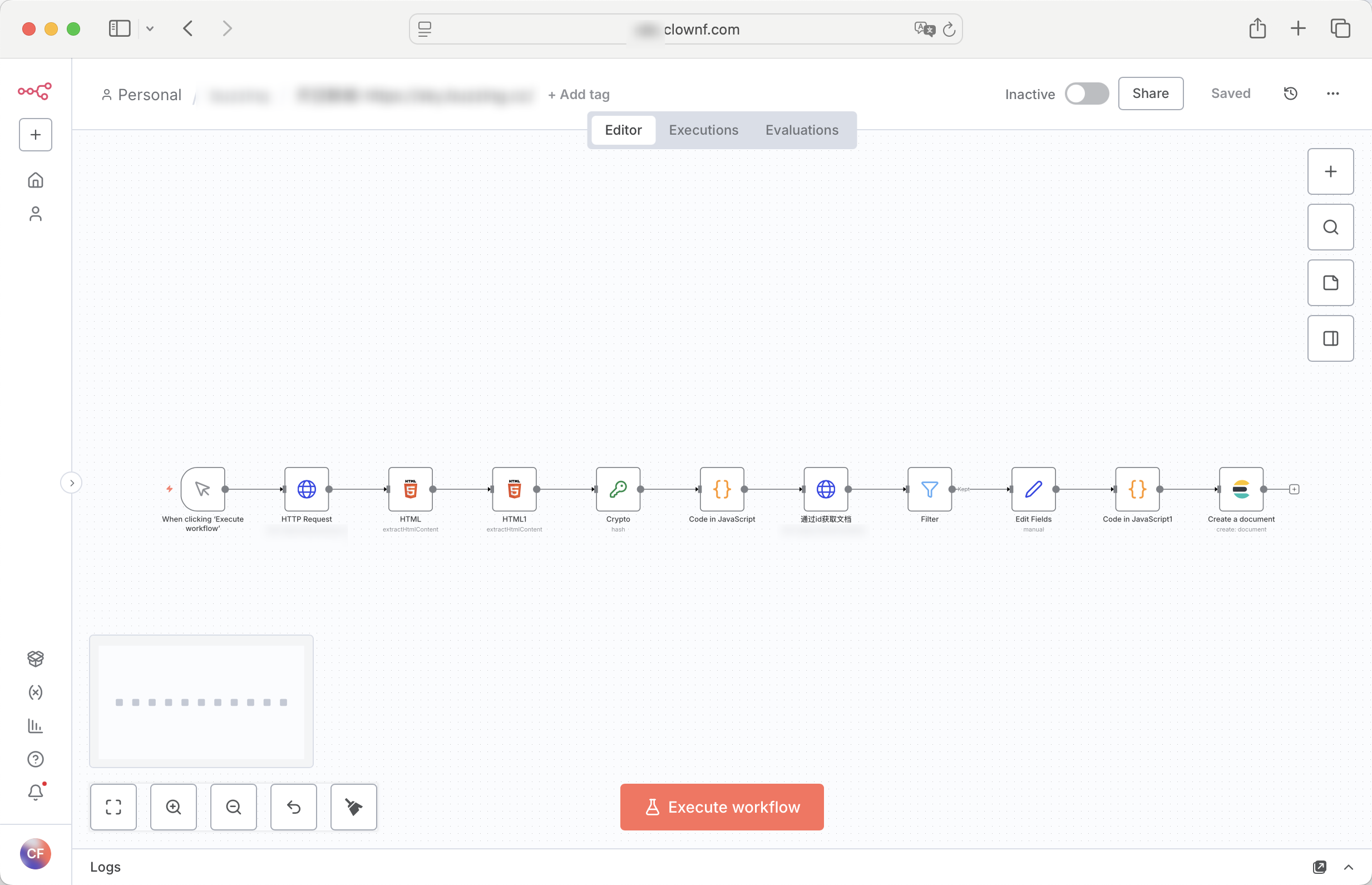
总结
初试 n8n,用来快速写简单爬虫倒是个不错的选择,但是复杂的爬虫,节点也会复杂。